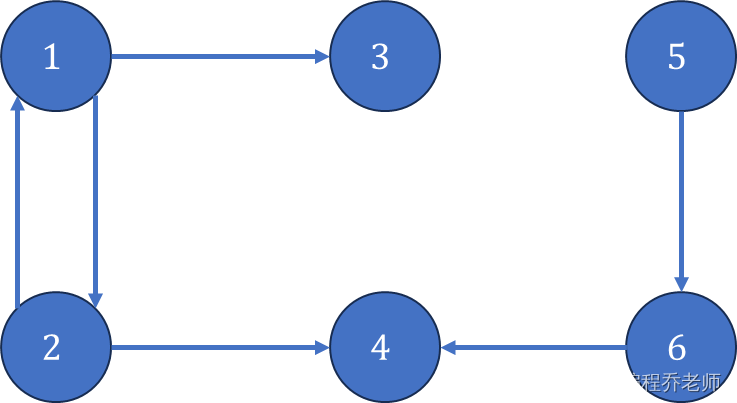
下载nginx搭建的文件服务器(爬虫)
windows版
需要下载python包:pip install requests
import requests
import re
import os
#开始访问的url地址,必须以/结尾
index_url = "https://www.aaa.com/aaaaa/"
#下载到本地的地址,必须以/结尾
local_address = "D:/up/"
def getHtml(index_url,local_address):
resp = requests.get(index_url)
html_content = resp.text
# 使用re.DOTALL标志使.匹配包括换行符在内的任何字符
pattern = re.compile(r'<a\s+[^>]*?>(.*?)</a>', re.DOTALL)
matches = pattern.findall(html_content)
for match in matches:
if("../"!=match):
if("/"==match[-1]):
#递归
dg_url = index_url+match
dg_local_address = local_address+match
getHtml(dg_url,dg_local_address)
else:
hq_index_url = index_url+match
hq_local_address = local_address+match
print(hq_index_url+"=========="+hq_local_address)
downFile(hq_index_url,hq_local_address)
# 获取内容,并下载
def downFile(url,local_address):
# 创建目录
# 分离目录和文件名
directory, filename = os.path.split(local_address)
# 检查目录是否存在,如果不存在则创建
if not os.path.exists(directory):
os.makedirs(directory)
response = requests.get(url, stream=True) # 使用stream=True以节省内存
# 检查响应状态码
if response.status_code == 200:
# 打开文件以二进制写入模式
with open(local_address, 'wb') as f:
# 迭代响应内容
for chunk in response.iter_content(chunk_size=8192):
# 如果chunk存在,则写入文件
if chunk:
f.write(chunk)
else:
print("下载出错:"+url)
getHtml(index_url,local_address)
![[leetcode hot 150]第三题,无重复字符的最长子串](https://img-blog.csdnimg.cn/direct/23c8fc5589dd443d8551ae4b06ab7712.png)